Pourquoi l'anglais est la langue privilégiée pour la tokenisation GPT-4
Pourquoi l’anglais est la langue privilégiée pour la tokenisation GPT-4
La tokenisation est un processus fondamental dans la transformation des textes en données numériques pour des modèles d’apprentissage automatique tels que GPT-4. Cependant, toutes les langues ne sont pas traitées de manière égale. L’anglais, en raison de biais historiques et techniques, reste la langue dominante dans le processus de tokenisation de GPT-4. Mais pourquoi ? Explorons cela.
🧐 Comprendre la Tokenisation
La tokenisation est le processus qui consiste à diviser un texte en composants plus petits appelés tokens. Ces tokens peuvent être des mots, des sous-mots ou même des caractères. Dans GPT-4, un token peut représenter des mots entiers en anglais, tandis que dans d’autres langues, les mots sont souvent divisés en sous-mots.
Exemple de Tokenisation
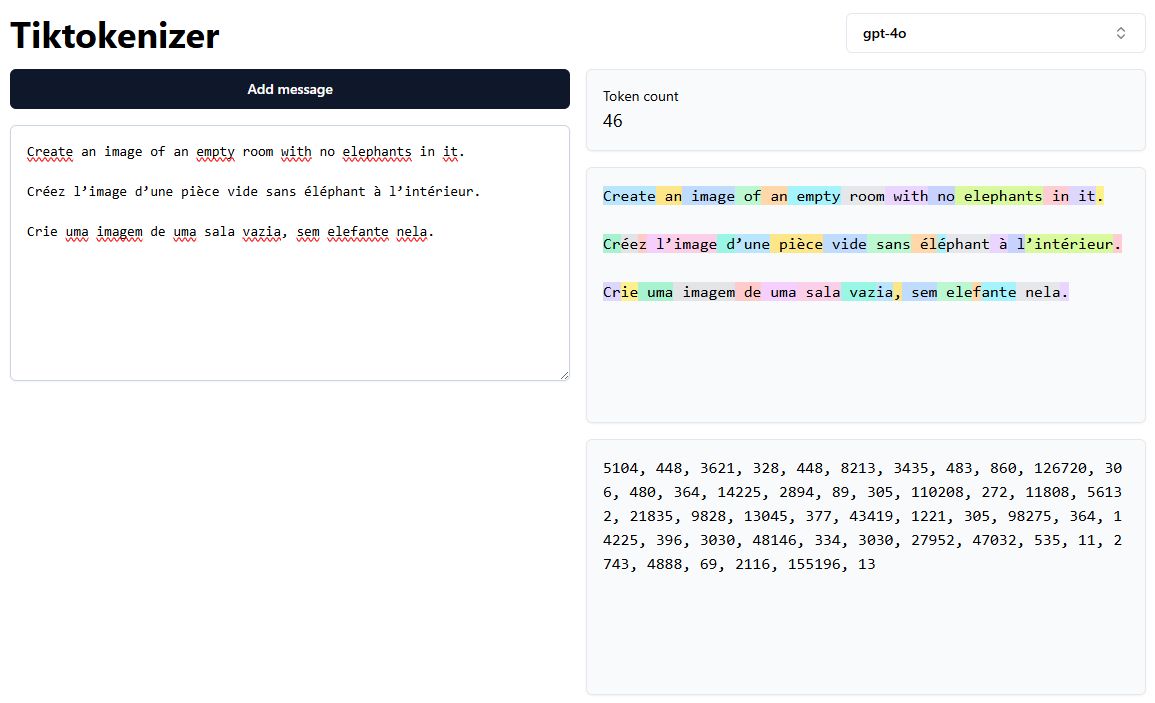
Dans l’image ci-dessous, nous voyons comment la phrase “Create an image of an empty room with no elephants in it” est tokenisée différemment en anglais, français et portugais :
- Anglais : Les mots sont principalement conservés intacts en tant que tokens entiers.
- Français : Certains mots sont segmentés en plusieurs tokens.
- Portugais : Le nombre de tokens est encore plus élevé, augmentant la complexité.
📦 Plus de Tokens, Plus de Complexité
Plus il y a de tokens, plus le modèle doit effectuer de calculs pour traiter le même contenu. Cette augmentation du nombre de tokens peut entraîner des coûts plus élevés, des temps de traitement plus longs et une fragmentation contextuelle, notamment dans les langues où les mots sont plus souvent découpés en sous-mots.
Dans l’exemple ci-dessus, la même phrase compte 14 tokens en anglais, mais 17 en français et 19 en portugais. Cette disparité est une conséquence directe de la stratégie de tokenisation et de la conception du tokenizer.
🤖 Pourquoi l’anglais domine-t-il ?
-
Disponibilité des données :
- L’internet est dominé par le contenu en anglais, offrant ainsi plus de données d’entraînement pour les modèles.
-
Biais de la Silicon Valley :
- Les grands laboratoires d’IA tels que OpenAI, Google et Anthropic sont basés aux États-Unis, où l’anglais est la langue principale.
-
Conception des tokenizers :
- Les tokenizers originaux ont été conçus en se concentrant sur l’anglais, ce qui permet de représenter des mots entiers en un seul token.
🌐 Implications pour l’IA multilingue
- Les modèles peuvent être moins efficaces pour les langues non anglaises en raison de l’augmentation du nombre de tokens.
- La segmentation en sous-mots peut entraîner une fragmentation sémantique, affectant la compréhension contextuelle.
- Les développeurs travaillant avec des langues non anglaises doivent tenir compte de ces biais de tokenisation.
🚀 Conclusion
La dominance de l’anglais dans la tokenisation GPT-4 est le résultat de la disponibilité des données, des pratiques d’entraînement des modèles et de la conception des tokenizers. À mesure que l’IA multilingue évolue, il sera crucial de repenser les stratégies de tokenisation pour réduire la complexité des tokens dans les langues non anglaises.
Hashtags : #IA #LLM #Tokenisation #IA_Multilingue #GPT4