Why English is the Preferred Language for GPT-4 Tokenization
Why English is the Preferred Language for GPT-4 Tokenization
Tokenization is a fundamental process in transforming text into numerical data for machine learning models like GPT-4. However, not all languages are treated equally in this process. English, due to historical and technical biases, remains the dominant language in GPT-4 tokenization. But why is this the case? Let’s explore.
🧐 Understanding Tokenization
Tokenization is the process of breaking down text into smaller components, known as tokens. These tokens can be words, subwords, or even characters. In GPT-4, a token can represent entire words in English, while in other languages, words are often broken down into subwords.
Example of Tokenization
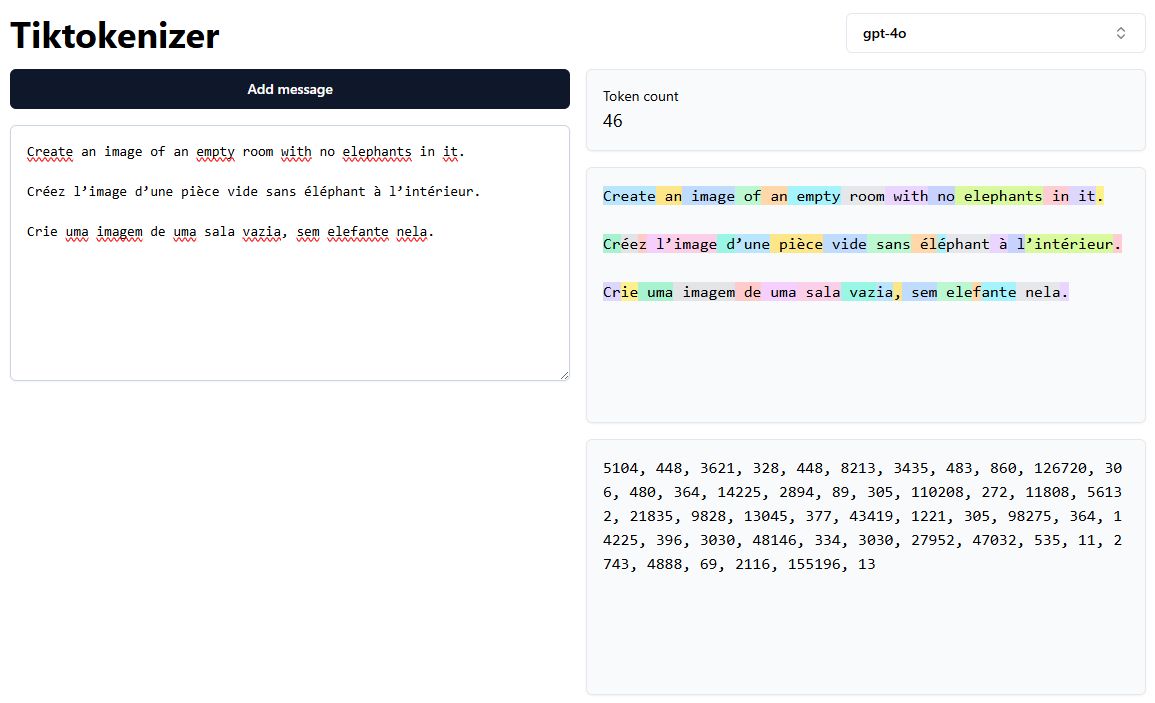
In the image below, we can see how the sentence “Create an image of an empty room with no elephants in it” is tokenized differently in English, French, and Portuguese:
- English: Words are largely kept intact as whole tokens.
- French: Some words are segmented into multiple tokens.
- Portuguese: More subword tokens are generated, increasing the token count.
📦 More Tokens, More Complexity
More tokens mean more computational steps for the model to process the same content. This increased token count can lead to higher costs, longer processing times, and potential context fragmentation, especially in languages where words are more frequently split into subwords.
In the example above, the same sentence has 14 tokens in English but results in 17 tokens in French and 19 tokens in Portuguese. This disparity is a direct consequence of the tokenization strategy and the design of the tokenizer.
🤖 Why English Dominates
-
Data Availability:
- The internet is dominated by English content, leading to more training data for English text.
-
Bay Area Bias:
- Major AI labs like OpenAI, Google, and Anthropic are based in the United States, where English is the primary language.
-
Tokenizer Design:
- The original tokenizers were designed with a focus on English, making it more efficient in representing English words as single tokens.
🌐 Implications for Multilingual AI
- Models may be less efficient in handling non-English languages due to increased token counts.
- Subword segmentation can lead to semantic fragmentation, affecting contextual understanding.
- Developers working with non-English languages should consider these tokenization biases when building applications.
🚀 Conclusion
The dominance of English in GPT-4 tokenization is a byproduct of data availability, model training practices, and tokenization design. As multilingual AI continues to evolve, rethinking tokenizer strategies to reduce token complexity in non-English languages will be crucial to achieving more equitable and efficient language models.
Hashtags: #AI #LLM #Tokenization #MultilingualAI #GPT4