Por Que o Inglês é a Língua Preferida para a Tokenização no GPT-4
Por Que o Inglês é a Língua Preferida para a Tokenização no GPT-4
A tokenização é um processo fundamental na transformação de textos em dados numéricos para modelos de aprendizado de máquina como o GPT-4. No entanto, nem todas as línguas são tratadas da mesma forma. O inglês, devido a preconceitos históricos e técnicos, permanece a língua dominante no processo de tokenização do GPT-4. Mas por quê? Vamos explorar.
🧐 Entendendo a Tokenização
Tokenização é o processo de dividir um texto em componentes menores chamados tokens. Esses tokens podem ser palavras, subpalavras ou até mesmo caracteres. No GPT-4, um token pode representar palavras inteiras em inglês, enquanto em outras línguas as palavras são frequentemente divididas em subpalavras.
Exemplo de Tokenização
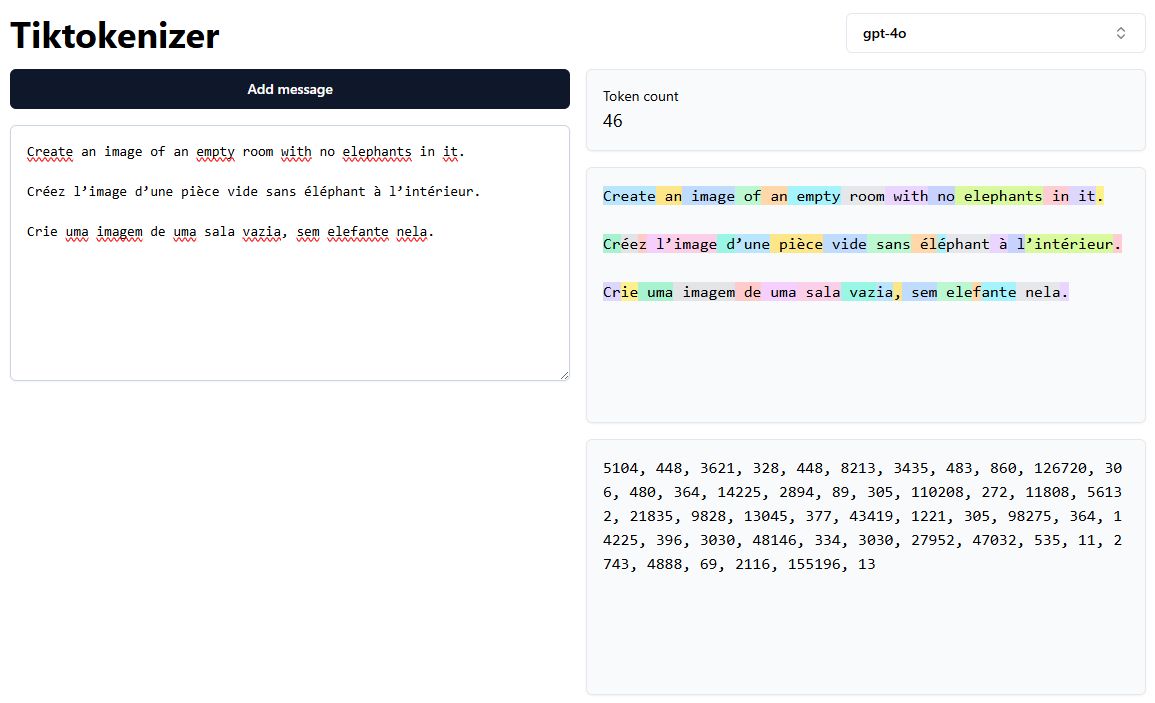
Na imagem abaixo, podemos ver como a frase “Create an image of an empty room with no elephants in it” é tokenizada de forma diferente em inglês, francês e português:
- Inglês: As palavras são mantidas principalmente como tokens inteiros.
- Francês: Algumas palavras são segmentadas em múltiplos tokens.
- Português: Mais tokens são gerados, aumentando a complexidade.
📦 Mais Tokens, Mais Complexidade
Mais tokens significam mais etapas computacionais para o modelo processar o mesmo conteúdo. Esse aumento na contagem de tokens pode levar a custos mais altos, tempos de processamento mais longos e fragmentação de contexto, especialmente em línguas onde as palavras são divididas em subpalavras.
No exemplo acima, a mesma frase possui 14 tokens em inglês, mas 17 em francês e 19 em português. Essa disparidade é uma consequência direta da estratégia de tokenização e do design do tokenizer.
🤖 Por Que o Inglês Domina?
-
Disponibilidade de Dados:
- A internet é dominada por conteúdo em inglês, proporcionando mais dados de treinamento.
-
Viés do Vale do Silício:
- Grandes laboratórios de IA como OpenAI, Google e Anthropic estão sediados nos Estados Unidos, onde o inglês é a língua principal.
-
Design dos Tokenizers:
- Os tokenizers foram inicialmente projetados com foco no inglês, permitindo que palavras inteiras sejam representadas em um único token.
🌐 Implicações para a IA Multilíngue
- Os modelos podem ser menos eficientes no processamento de línguas não inglesas devido ao aumento da contagem de tokens.
- A segmentação em subpalavras pode fragmentar o contexto, prejudicando a compreensão.
- Desenvolvedores que trabalham com línguas não inglesas devem considerar esses vieses na tokenização.
🚀 Conclusão
A dominância do inglês na tokenização GPT-4 é resultado da disponibilidade de dados, das práticas de treinamento e do design dos tokenizers. À medida que a IA multilíngue evolui, será essencial repensar as estratégias de tokenização para reduzir a complexidade dos tokens em línguas não inglesas.
Hashtags: #IA #LLM #Tokenização #AIMultilíngue #GPT4